Biography
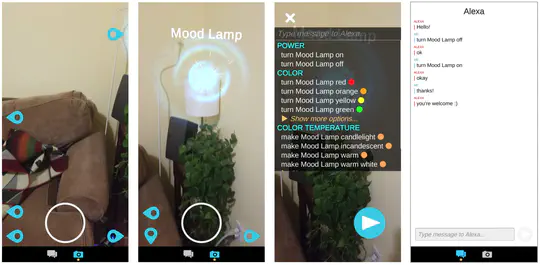
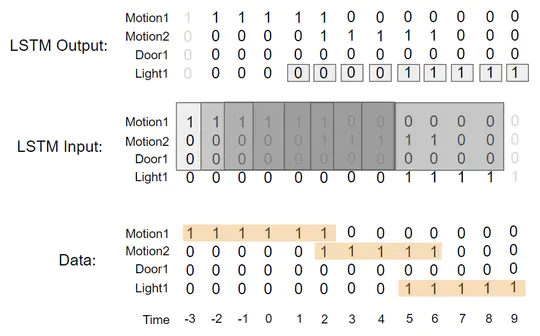
I have ten years of experience developing end-to-end solutions at the intersection of IoT, mixed reality, and AI. I hold a PhD in computer science from UC Berkeley, where I focused on smart buildings. I also completed a postdoc on capturing and visualizing wireless network traffic. I’m interested in distributing computation across cloud-edge architectures, particularly to support IoT and networking applications.
9/12/22: I’m excited to announce that I have joined the Innovation Team at Resideo Technologies as an IoT Systems Research Scientist!
Download my resumé.
- Network monitoring
- Sensor networks/IoT
- Microservice architectures
- Observability
-
PhD in Computer Science, 2021
University of California, Berkeley
-
MS in Computer Science and Engineering, 2017
University of Michigan
-
BS in Computer Science, 2011
George Mason University
Projects